Using Core ML in iOS from A to Z

Core ML (Core Machine Learning) has been released by Apple in iOS 11. There are many articles about “How to using Core ML in iOS”. However, in those articles, authors just told “How to USING the created model” but they didn’t talk “How to CREATE a model”, so I write this article to introduce how to using Core ML from scratch, include how to create a model by yourself.
Let’s start!
You can download the dataset that I use in this article here
I. The dataset
In this dataset, we have 5 fields: UserID, Gender, Age, EstimatedSalary, Purchased. From this dataset, I want to create a simple DSS (Decision Support System) is: Decide to purchase or not by using Age and Estimated Salary.
II. Create training model
1. Preparing
1.1. Python
Check your python version by using this command:
python — version
The reason we need to check python version because we need python version 2.7, if your python is version above 3.0, you need to install python version 2.7.
Why? I’ll talk in next section.
1.2. Install coremltools
Apple has provided a tool has name coremltools to convert a model has been created by python to model that can use in iOS.
coremltools only run with python version 2.7, that is the reason I told you install python 2.7 in previous section. In past, my machine has python 3.6 so I can’t using coremltools.
If your machine only has python 2.7, just open the terminal and enter:
pip install coremltools
If your machine has both python 3.x and python 2.7, open the terminal and enter:
sudo pip2 install coremltools
For more details about install coremltools
1.3. Install other packages for machine learning
Depend of your machine learning method, you need other packages, just visit https://apple.github.io/coremltools/ for more details.
In this article, we need these packages: sklearn, numpy, pandas (Google for how to install these packages).
Note: Install these packages with python 2.7
2. Create the model by python
For example, I use Linear SVM and I create a python file has name svm.py with content:
import numpy as np
import pandas as pd
import pickle
To read dataset from dataset file, continue with svm.py:
# Import dataset
dataset = pd.read_csv(‘Social_Network_Ads.csv’);
# Read data from Age, EstimatedSalary
X = dataset.iloc[:, [2,3]].values
# Read data from Purchased
y = dataset.iloc[:, 4].values
Because values of Age and EstimatedSalary have a large gap so we need to standardize them to a same field to avoid wrong result.
Why? I couldn't answer here because it's about another domain: MACHINE LEARNING. So you need to read about machine learning to understand why.
Continue with svm.py:
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X = sc.fit_transform(X)
#Create the classifier
from sklearn import svm
classsifier = svm.SVC(kernel=’linear’, C=1.0)
classsifier.fit(X,y)
#save the model to disk
from sklearn.externals import joblib
filename = ‘Social_Network_Ads_model.sav’
pickle.dump(classsifier, open(filename, ‘wb’))
Now, open your terminal and enter:
python svm.py
If you have both python 3.x and python 2.7:
python2.7 svm.py
3. Create model for Core ML
Create another file has name extract_model.py with content:
import coremltools
from sklearn.externals import joblib
#Load the created model
classifier = joblib.load(‘Social_Network_Ads_model.sav’)
#Convert the created model to Core ML model
coremlModel = coremltools.converters.sklearn.convert(classifier, [“Age”,”EstimatedSalary”],”Purchased”)
# Save the converted model
coremlModel.save(‘SocialNetworkAds.mlmodel’)
III. Using the model
I create a demo project has name DemoAI look like:

Drag and drop file SocialNetworkAds.mlmodel to project, select this file we will see:
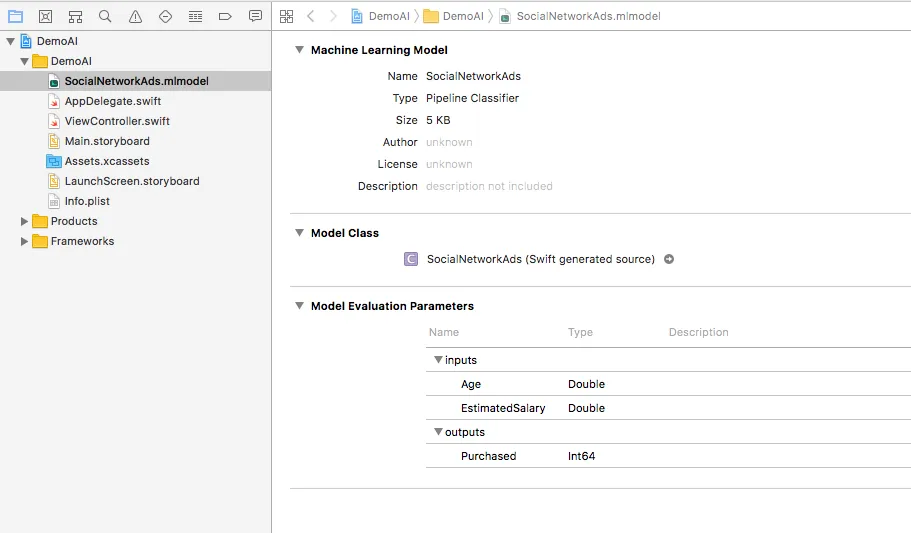
Look at section Model Class, check the Target Membership box if you don’t see the message Swift generated source

Xcode will generate a Object with name is the name of model file that we have imported to project.
Open ViewController.swift and modify like this:
import UIKit
class ViewController: UIViewController {
@IBOutlet weak var txtAge: UITextField!
@IBOutlet weak var txtEstimatedSalary: UITextField!
@IBOutlet weak var lblResult: UILabel!
var model: SocialNetworkAds!
override func viewDidLoad() {
super.viewDidLoad()
model = SocialNetworkAds()
}
@IBOutlet func predict(_ sender: Any) {
let age = self.txtAge.text
let salary = self.txtEstimatedSalary.text
if (age != "" && salary !== "") {
let inputToPredict = SocialNetworkAdsInput(Age: (Double(age!))!, EstimatedSalary: (Double(salary!))!)
guard let outputPredicted = try? model.prediction(input: inputToPredict) else {
fatalError("Unexpected runtime error.")
}
if (outputPredicted.Purchased == 0) {
self.lblResult.text = "NO"
} else {
elf.lblResult.text = "YES"
}
}
}
}
Now, run the app and enjoy!
Happy Coding! Good luck!